前段时间我排查了一个线上的Go语言服务的内存泄漏问题,感觉是一次有价值的经验。特将排查过程记录下来,供大家参考。
1. 问题发现
我负责维护的某个Go语言模块,在某次功能上线过了两天左右,被OP同学发现所有pod在相近的时间都重启了一次,对线上流量也产生了影响,开始拉群讨论。
2. 紧急处理
通过kubectl get pod xxx -oyaml命令可以看到pod最近一次重启的原因是"OOM Killed",所有pod都发生OOM,基本可以确定是内存泄漏问题。但内存泄漏问题可能无法短时间定位原因,所以我和OP商量,决定临时将所有pod的内存限制扩大1倍,这样可以将下次OOM的时间延后,在这段时间内,我需要找出OOM的根因并修复上线。
3. 问题排查
3.1. 尝试复现
排查内存泄漏的问题,首先需要尝试复现。线上服务出于性能考虑,没有开启pprof,无法查看运行时的内存占用情况,我们只能在线下环境尝试复现。
开启pprof的代码如下:
package main
import (
"fmt"
// 重点1,需要直接引入pprof包,触发其内部的初始化逻辑
_ "net/http/pprof"
"net/http"
)
func main() {
// 重点2
if options.GetConfig().Server.PprofEnable {
go func() {
fmt.Print("start pprof")
if err := http.ListenAndServe("0.0.0.0:"+options.GetConfig().Server.PprofPort, nil); err != nil {
fmt.Print("pprof start failed: ", err)
}
}()
}
// 启动http服务
}
在配置文件的对应位置填上正确的pprof端口:
pprof_enable: true
pprof_port: 8899修改完代码后部署到线下测试环境,然后在浏览器访问http://{test_ip}:8899/debug/pprof/,如果可以访问通,证明pprof开启成功。
用jmatter发请求,观察pprof信息。可以发现goroutine一直在增加:

点进去可以发现是固定的某个逻辑创建的goroutine一直在增加,没有减少:
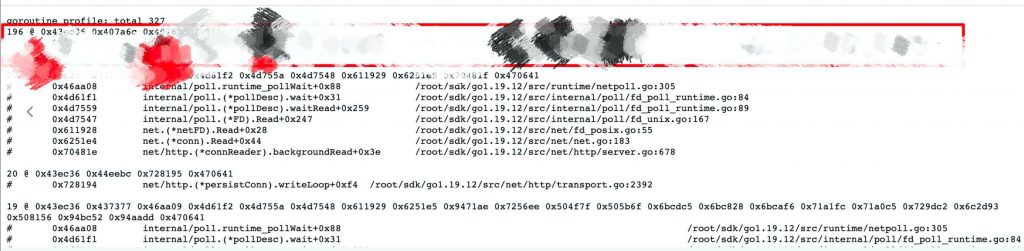
到此,基本可以确定是协程泄漏导致的协程占用的内存泄漏。
go语言的内存泄漏,绝大多数情况都是goroutine泄漏,否则正常情况下创建的对象、占用的内存都会被回收。
查看代码后,可以发现是在两个协程基于channel通信时逻辑错误,导致的协程泄漏,代码大致如下:
func callModelAndProcess(c *gin.Context) {
msgCh := make(chan *http.Event)
errCh := make(chan error)
go func(msgCh chan *http.Event, errCh chan error) {
for {
event, err := reader.ReadEvent()
// 本协程是个死循环,唯一退出路径是从下游服务response中读到EOF或者其他错误,然后向errCh中写入错误
// 而errCh是无缓冲区的,所以如果没有其他协程在读取errCh,那么这个协程就会阻塞在这里
if err != nil {
errCh <- err
req.Close()
return
}
var msg *Event
if msg, err = ProcessEventNew(event); err == nil {
if msg.hasContent() {
msgCh <- msg
}
}
}
}(msgCh, errCh)
timeout := time.After(time.Second * time.Duration(options.GetConfig().ErnieBot.Timeout))
for {
// 在主协程中,对于timeout或在处理msg时出错的情况,会直接return,就不再监听errCh了,
// 这种情况下,上面的协程就会阻塞在errCh的写入,导致goroutine泄露
select {
case <-timeout:
return
case _ = <-errCh:
return
case msg := <-msgCh:
if err := handleMsg(msg); err != nil {
return
}
fmt.Fprint(c.Writer, string(msg.RawMsg)+"\n\n")
c.Writer.Flush()
// 如果是最后一句,返回(其实不应该返回)
if isEnd {
return
}
}
}
}可以看到,读取response的子协程要想结束,必须从response中读到EOF(响应结束)或读取失败,然后将错误写出到errCh管道中,而errCh管道没有缓冲区,也就是说,主协程必须在读到errCh的数据后,才能返回,否则就会导致子协程阻塞在写出到errCh的代码上。
而主协程有多个提前退出的逻辑:处理msg失败,处理完最后一条msg,超时,以及读取到errCh。如果是经由读取到errCh之外的其他路径退出,就会导致子协程阻塞,子协程持有response body对象,body对象中包含响应体,内存占用很大,时间长了,必然会OOM。
4. 解决方案
两种方案:
- 保证除了从errCh收到消息之外的其他路径,都不return,确保最后从errCh结束
- 给errCh增加一个元素的缓冲区,保证协程写入channel不被阻塞,这样协程可以正常结束,主协程退出后errCh会被垃圾回收
我最终采取了第2种方案。因为第1种方案并不保险,后续修改时可能一不注意就会写出提前返回的逻辑,导致协程泄漏。第2种方案是相对稳定的方案。