写在前面
在如今的2025年,对于大部分程序员来说,或多或少都听说过或实际使用过大模型,不止是简单的通过页面或接口进行模型推理,可能还实际做过大模型的训练,当然,指的是SFT,也就是用少量的、特定领域、特定格式的数据训练,让大模型更适应特定的任务。但我估计,大部分SFT任务应该都是通过如火山方舟、文心千帆等大模型平台做的,只需要上传一个数据文件,点几下按钮,平台就会自动帮你做训练,训练完成后可以零代码地帮你评估模型效果、再帮你部署上去,你直接调用新模型的推理接口即可。
这样的平台当然简化了业务系统研发使用大模型的门槛,但对于大模型研发部分的同学来说,只掌握平台操作当然是不够的,还需要深入到代码层面,看看在平台上点一下“开始训练”的按钮后,后台实际做了什么。
本文就旨在通过手把手的演示,带大家走一遍代码级的大模型推理、评估、SFT的过程,作为一篇类似综述的文章,带大家走进大模型的底层世界。
前置准备
本文面向的是有一定编程和大模型概念的研发同学,所以在开始之前,请确认下你是否有以下方面的经验或概念?
- 有Python语言开发经验,或能看懂Python的代码
- 知道大模型的概念,了解大模型训练、SFT、推理是指什么
- 知道huggingFace、github是什么
另外,由于国内的特殊环境(great well),为了后续操作能顺利进行,请你确认下你的电脑环境,如果能和下面列出的我的环境保持一致那就最好了,否则你可能会遇到一些我没遇到过的问题,我不确实是否能帮你解决:
- 电脑配置:MacBook Pro,M3芯片,系统版本:14.6.1 (23G93),36G内存
- 网络环境能访问huggingface和github
模型推理和评估
让我们从最简单的直接使用开源模型进行推理开始。
我们以Qwen/Qwen2.5-3B-Instruct模型为例,3B的模型可能在Mac本地使用CPU进行推理,避免了我们没有GPU资源的尴尬。
开发环境准备
可以用PyCharm新建个项目,这样PyCharm会帮我们建好venv环境,对于对Python开发环境不熟的同学是个利好。

如上图所示,我用的是Python3.9.6版本,大家尽量也使用3.9.x版本,以免后面出现因为版本问题导致的不兼容问题(llm推理和训练用到的包很多,兼容性做的不太好)。
新建项目后,在命令行可以看到目前已经处在venv环境里,下面配置下pip源,并安装依赖:
# 添加pip源
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip config set install.trusted-host http://mirrors.aliyun.com
# 安装大模型推理代码的依赖
pip install transformers
pip install torch模型推理
新建文件origin_infer.py,内容如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
# 创建model和tokenizer对象,默认会从huggingFace上下载对应的模型,这里的Qwen/Qwen2.5-3B-Instruct就是huggingFace上的模型名
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-3B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-3B-Instruct")
# 构造对话的system prompt和user prompt
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": "Who are you?"},
]
# 通过官方tokenizer提供的方法,把人类可读的messages转化为llm可读的文本(通过特殊token分隔的prompt)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# 把文本转换为tokens
model_inputs = tokenizer([text], return_tensors="pt")
# 调用模型进行生成
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
)
# 由于返回的generated_ids会包含所有输入的inputs和新生成的ids,这里做一个截取,把前面的inputs去掉,只保留后面新生成的ids
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 把tokens转换为可读的文本
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("response: ", response)
上面就是使用transformers包进行推理的基础代码,transformers包是大模型训练推理方面一个中间层的包,它封装了像模型加载、输入输出文本tokenize等等的方法,让我们能简单地使用大模型,当然,它的下层还有更底层的包,它的上层有各种只需一行就能做推理、训练的包,不过,如果要学习大模型的用法,transformers包还是必学不可的。
上面的代码执行后,在日志里会打印出模型下载、模型加载、推理结果3个步骤:
/Users/bytedance/PycharmProjects/llm_sft_demo/.venv/bin/python /Users/bytedance/PycharmProjects/llm_sft_demo/origin_infer.py
/Users/bytedance/PycharmProjects/llm_sft_demo/.venv/lib/python3.9/site-packages/urllib3/__init__.py:35: NotOpenSSLWarning: urllib3 v2 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'LibreSSL 2.8.3'. See: https://github.com/urllib3/urllib3/issues/3020
warnings.warn(
Sliding Window Attention is enabled but not implemented for `sdpa`; unexpected results may be encountered.
Loading checkpoint shards: 100%|██████████| 2/2 [00:04<00:00, 2.42s/it]
response: I am Qwen, a large language model created by Alibaba Cloud. I'm here to assist you with a wide range of tasks and questions to the best of my ability. How can I help you today?
Process finished with exit code 0
这是我的输出,因为我已经提前下载好了模型,所以这里没有模型下载的日志。
现在,我们已经能够用代码加载开源模型并进行推理了,现在,让我们看看如何测评一个大模型。
模型测评(刷榜)
过去的两年里,每当有新的大模型发布时,官方总免不了说自己的模型多么优秀,又把openai的模型甩到了多么后面,这时总会给出一张对比图,说自己的模型在某某榜单上超过了openai多少,这其实就是刷榜的过程。
目前对大模型进行评估的数据集有很多,有客观题的,有主观题的,有人文类的,有科学类的。通常一个数据集会包含多条数据,每条数据都是一个Q&A对,用Q去问大模型,拿到大模型的回答后,看是否是正确的,正确则加分,错误则不加分,最后,得到总分。每个数据集都可以出一个榜单,记录每个模型在该数据集上的得分并排名。我们以一个中文领域最简单的数据集C-Eval为例,测一下Qwen2.5-3B-Instruct在这个数据集上能得分多少分。
作为一个程序员,很容易能想到要测试某个模型在某个数据集上的得分,要有以下几个步骤:
- 下载数据集
- 对数据集里每个问题调用大模型推理,拿到结果
- 整理出一份大模型的结果列表,对比正确答案,计算得分
不过这些基本都是流成性的代码,编写起来工作量大,又没什么实际意义,幸好,有好心人已经提前开发病开源了评估的代码库,我们可以直接用。这里,我们用lm-evaluation-harness这个库。
使用方法如下:
# 下载源码
git clone --depth 1 https://github.com/EleutherAI/lm-evaluation-harness
# 安装依赖
cd lm-evaluation-harness
pip install -e .
# 用C-Eval数据集里的chinese_language_and_literature部分测试下Qwen2.5-3B-Instruct的能力,看它能得多少分
python -m lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-3B-Instruct \
--tasks ceval-valid_chinese_language_and_literature \
--device cpu \
--batch_size 8 \
--output_path ./output \
--log_samples输出结果:
/Users/bytedance/PycharmProjects/llm_sft_demo/.venv/lib/python3.9/site-packages/urllib3/__init__.py:35: NotOpenSSLWarning: urllib3 v2 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'LibreSSL 2.8.3'. See: https://github.com/urllib3/urllib3/issues/3020
warnings.warn(
2025-05-02:18:43:50 INFO [__main__:440] Selected Tasks: ['ceval-valid_chinese_language_and_literature']
2025-05-02:18:43:50 INFO [evaluator:185] Setting random seed to 0 | Setting numpy seed to 1234 | Setting torch manual seed to 1234 | Setting fewshot manual seed to 1234
2025-05-02:18:43:50 INFO [evaluator:223] Initializing hf model, with arguments: {'pretrained': 'Qwen/Qwen2.5-3B-Instruct'}
2025-05-02:18:43:50 INFO [models.huggingface:137] Using device 'cpu'
2025-05-02:18:43:52 INFO [models.huggingface:382] Model parallel was set to False, max memory was not set, and device map was set to {'': 'cpu'}
Sliding Window Attention is enabled but not implemented for `sdpa`; unexpected results may be encountered.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 10.52it/s]
2025-05-02:18:44:02 INFO [api.task:434] Building contexts for ceval-valid_chinese_language_and_literature on rank 0...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 23/23 [00:00<00:00, 1416.27it/s]
2025-05-02:18:44:02 INFO [evaluator:559] Running loglikelihood requests
Running loglikelihood requests: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 92/92 [00:50<00:00, 1.81it/s]
2025-05-02:18:44:54 INFO [loggers.evaluation_tracker:209] Saving results aggregated
2025-05-02:18:44:54 INFO [loggers.evaluation_tracker:290] Saving per-sample results for: ceval-valid_chinese_language_and_literature
hf (pretrained=Qwen/Qwen2.5-3B-Instruct), gen_kwargs: (None), limit: None, num_fewshot: None, batch_size: 8
| Tasks |Version|Filter|n-shot| Metric | |Value | |Stderr|
|-------------------------------------------|------:|------|-----:|--------|---|-----:|---|-----:|
|ceval-valid_chinese_language_and_literature| 2|none | 0|acc |↑ |0.5217|± |0.1065|
| | |none | 0|acc_norm|↑ |0.5217|± |0.1065|
可以看到最后,正确率得分:0.5217,这是官方的模型分数。
模型SFT
现在,假如我们收到一个任务:构建一个自己的模型,要求在C-Eval的chinese_language_and_literature数据榜单上排第一。关键我们只有一个人,还没什么资源,我们可以怎么做呢?相信你已经想到了取巧的方法:我直接用测评数据集的原题和答案去训练模型,这样模型甚至可以做到100%的正确率,可不就是排名第一了吗?这就开干!
温馨提示:这么做在大模型领域是非常不好的,有违职业道德,会被同行鄙视的
数据准备
首先,我们需要拿到测评数据集的原题和答案,可以去网上搜,也可以从huggingFace上下载,再人工作出答案,或者让厉害点的大模型算,这里我直接把文件内容贴出来:
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n英语名词“lab”(实验室)原来的形式是“laboratory”,这在词的形成方式上属于____。\nA.直接成词\nB.变形成词\nC.变性成词\nD.逆序成词\n答案:", "answer": "D"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n音位是____。\nA.最小的语音语义结合体\nB.一个语音系统中能区别意义的最小语音单位\nC.语言中最小的能区别意义的语音特征单位\nD.语言中有区别性特征的最小语音单位\n答案:", "answer": "B"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n下列语言中,属于印欧语系拉丁语族的语言是____。\nA.英语\nB.俄语\nC.德语\nD.法语\n答案:", "answer": "D"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n《史记·高祖本纪》:“今则来,沛公恐不得有此。”句中“则”的用法是____。\nA.表示承接\nB.表示转折\nC.表示假设\nD.表示因果\n答案:", "answer": "C"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n《四世同堂》中的冠晓荷是____。\nA.老派市民的形象\nB.革命者的形象\nC.正直的知识分子形象\nD.民族败类的形象\n答案:", "answer": "D"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n“塑”这个字的音节的声母是____。\nA.sh\nB.x\nC.s\nD.零声母\n答案:", "answer": "C"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n《论语·述而》:“若圣与仁,则吾岂敢?抑为之不厌,诲人不倦,则可谓云尔已矣。”句中“抑”的用法是____。\nA.表示假设\nB.表示转折\nC.表示原因\nD.表示目的\n答案:", "answer": "B"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n下列有歧义的一项是____。\nA.进口汽车\nB.路边种着树\nC.洗得干净\nD.咬死了猎人的鸡\n答案:", "answer": "D"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n[p][p‘][b][m]四个音素的区别主要是____。\nA.清浊\nB.发音方法\nC.发音部位\nD.送气与否\n答案:", "answer": "A"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n____是中国古代蒙学教育所采用的一种识字课本,由周兴嗣编撰而成。\nA.《三字经》\nB.《弟子规》\nC.《百家姓》\nD.《千字文》\n答案:", "answer": "D"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n卢舍那大佛是石窟雕塑中____的代表作。\nA.云冈石窟\nB.龙门石窟\nC.莫高窟\nD.麦积山石窟\n答案:", "answer": "B"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n目前最通用的楷书印刷体是____。\nA.宋体\nB.仿宋体\nC.楷体\nD.黑体\n答案:", "answer": "A"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n下列句中,不属于宾语前置的是____。\nA.姜氏何厌之有?\nB.斥鷃笑之曰:“彼且奚适也?”\nC.居则曰:“不吾知也!”\nD.胡不见我于王?\n答案:", "answer": "D"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n“员、可、乡、分、展、从”中包含的自由语素是____。\nA.乡、分、从\nB.可、分、展\nC.员、乡、分\nD.员、可、乡\n答案:", "answer": "A"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n《杜十娘怒沉百宝箱》出自____。\nA.《传奇》\nB.《聊斋志异》\nC.“三言”\nD.“二拍”\n答案:", "answer": "C"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n剧作家____被誉为“中国十六世纪的莎士比亚”。\nA.关汉卿\nB.白朴\nC.汤显祖\nD.马致远\n答案:", "answer": "C"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n《三国志·蜀书·诸葛亮传》:“每自比于管仲、乐毅,时人莫之许也。”句中“于”的用法是____。\nA.表对象\nB.表比较\nC.表原因\nD.表施事\n答案:", "answer": "A"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n《本草纲目》的作者是____李时珍。\nA.南宋人\nB.明朝人\nC.元朝人\nD.清朝人\n答案:", "answer": "B"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n“我、你、他”是____。\nA.指示代词\nB.疑问代词\nC.人称代词\nD.名词\n答案:", "answer": "C"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n关于词的本义和基本义的关系,下列表述正确的是____。\nA.完全不一致\nB.完全一致\nC.本义比基本义更常用\nD.基本义比本义更常用\n答案:", "answer": "D"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n“现在轮到你说了”是____。\nA.连谓句\nB.兼语句\nC.被动句\nD.双宾语句\n答案:", "answer": "B"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\n“队”与“坠”是____。\nA.古今字\nB.异体字\nC.通假字\nD.繁简字\n答案:", "answer": "A"}
{"prompt": "以下是中国关于中国语言文学的单项选择题,请选出其中的正确答案。\n\nd、t、n、l四个辅声的发音部位是____。\nA.舌尖前\nB.舌面\nC.舌尖中\nD.舌尖后\n答案:", "answer": "C"}代码训练
接下来,我们需要做SFT,但遗憾的是,SFT无论如何都是不可能在MAC上跑的,必须要有个GPU才行,这里我们可以白嫖阿里的ModelScope上的实例,每个用户都有免费的30多小时的使用额度。
先注册下ModelScope:https://modelscope.cn/
注册完后,在个人主页的“我的Notebook”里,启动GPU环境:
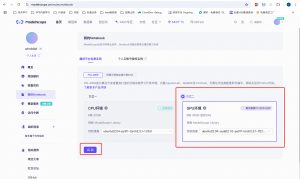
启动后,新建个文件new_train_data_2.jsonl,把上面的训练数据拷进去。再新建个notebook文件sft.ipynb,内容如下:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import get_model_tokenizer, load_dataset, get_template, EncodePreprocessor
from swift.utils import get_logger, find_all_linears, get_model_parameter_info, plot_images, seed_everything
from swift.tuners import Swift, LoraConfig
from swift.trainers import Seq2SeqTrainer, Seq2SeqTrainingArguments
from functools import partial
logger = get_logger()
seed_everything(42)
# Hyperparameters for training
# model
model_id_or_path = 'Qwen/Qwen2.5-3B-Instruct' # model_id or model_path
system = 'You are a helpful assistant.'
output_dir = 'output'
# dataset
dataset = ['./new_train_data_2.jsonl'] # dataset_id or dataset_path
data_seed = 42
max_length = 2048
split_dataset_ratio = 0.01 # Split validation set
num_proc = 4 # The number of processes for data loading.
# lora
lora_rank = 8
lora_alpha = 32
# training_args
training_args = Seq2SeqTrainingArguments(
output_dir=output_dir,
learning_rate=1e-4,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_checkpointing=True,
weight_decay=0.1,
lr_scheduler_type='cosine',
warmup_ratio=0.05,
report_to=['tensorboard'],
logging_first_step=True,
save_strategy='steps',
save_steps=50,
eval_strategy='steps',
eval_steps=50,
gradient_accumulation_steps=16,
num_train_epochs=40,
metric_for_best_model='loss',
save_total_limit=2,
logging_steps=5,
dataloader_num_workers=1,
data_seed=data_seed,
)
output_dir = os.path.abspath(os.path.expanduser(output_dir))
logger.info(f'output_dir: {output_dir}')
# Obtain the model and template, and add a trainable Lora layer on the model.
model, tokenizer = get_model_tokenizer(model_id_or_path)
logger.info(f'model_info: {model.model_info}')
template = get_template(model.model_meta.template, tokenizer, default_system=system, max_length=max_length)
template.set_mode('train')
target_modules = find_all_linears(model)
lora_config = LoraConfig(task_type='CAUSAL_LM', r=lora_rank, lora_alpha=lora_alpha,
target_modules=target_modules)
model = Swift.prepare_model(model, lora_config)
logger.info(f'lora_config: {lora_config}')
# Print model structure and trainable parameters.
logger.info(f'model: {model}')
model_parameter_info = get_model_parameter_info(model)
logger.info(f'model_parameter_info: {model_parameter_info}')
# Download and load the dataset, split it into a training set and a validation set,
# and encode the text data into tokens.
train_dataset, val_dataset = load_dataset(dataset, split_dataset_ratio=split_dataset_ratio, num_proc=num_proc,
seed=data_seed)
logger.info(f'train_dataset: {train_dataset}')
logger.info(f'val_dataset: {val_dataset}')
logger.info(f'train_dataset[0]: {train_dataset[0]}')
train_dataset = EncodePreprocessor(template=template)(train_dataset, num_proc=num_proc)
val_dataset = EncodePreprocessor(template=template)(val_dataset, num_proc=num_proc)
logger.info(f'encoded_train_dataset[0]: {train_dataset[0]}')
# Print a sample
template.print_inputs(train_dataset[0])
# Get the trainer and start the training.
model.enable_input_require_grads() # Compatible with gradient checkpointing
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
data_collator=template.data_collator,
train_dataset=train_dataset,
eval_dataset=val_dataset,
template=template,
)
trainer.train()
last_model_checkpoint = trainer.state.last_model_checkpoint
logger.info(f'last_model_checkpoint: {last_model_checkpoint}')
# Visualize the training loss.
# You can also use the TensorBoard visualization interface during training by entering
# `tensorboard --logdir '{output_dir}/runs'` at the command line.
images_dir = os.path.join(output_dir, 'images')
logger.info(f'images_dir: {images_dir}')
plot_images(images_dir, training_args.logging_dir, ['train/loss'], 0.9) # save images
# Read and display the image.
# The light yellow line represents the actual loss value,
# while the yellow line represents the loss value smoothed with a smoothing factor of 0.9.
from IPython.display import display
from PIL import Image
image = Image.open(os.path.join(images_dir, 'train_loss.png'))
display(image)以上就是完整的训练代码,亲测跑起来大概一分多钟就能跑完。
上面的代码你可能看得很懵,明明python语法我也知道,为啥就是看不懂代码在干啥呢?这很正常,我也看不懂上面的代码,只知道个大概的概念,比如上面这坨代码会用我们给的训练数据训出一个小模型,类似插件模型,在推理时推理接口支持传入一个基础模型,一个插件模型,在推理时能把两个模型拼起来一起推理。最后,在训练后还会打印出一个loss的图,表明模型在训练数据上拟合程度越来越高。
训练完成后,会在output目录下生成一个checkpoint-40的文件夹,这个文件夹就是我们训出来的小模型。我们可以把模型下载下来,再次测评下,看看我们“精心”训练出来的模型,能不能在指定的数据集上拿第一。
再次测评
先在notebook上把checkpoint-40文件夹打包下载下来:
cd output/
zip -r checkpoint-40.zip checkpoint-40回到本地的lm-evaluation-harness项目根目录,把下载下来的小模型放进来,再重新测评:
mkdir lora
mv ~/Downloads/checkpoint-40.zip ./lora
cd lora
unzip checkpoint-40.zip
python -m lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-3B-Instruct,peft=lora/checkpoint-40 \
--tasks ceval-valid_chinese_language_and_literature \
--device cpu \
--batch_size 8 \
--output_path ./output \
--log_samples执行上面的命令后,你会发现。。。。。。报错啦!类似下面的报错:
RuntimeError: Placeholder storage has not been allocated on MPS device!没错,lm-evaluation-harness这个项目对于lora模型在Mac上的运行有点问题,我们需要改点源码才能正常跑:
vi lm_eval/models/huggingface.py
# 在文件中搜索“PeftModel.from_pretrained”,在这个函数入参里增加两个字段:“torch_device="cpu", device_map={"": "cpu"}”,如下:
self._model = PeftModel.from_pretrained(
self._model, peft, revision=revision, torch_device="cpu", device_map={"": "cpu"}
)保存退出,再次执行测评命令:
python -m lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-3B-Instruct,peft=lora/checkpoint-40 \
--tasks ceval-valid_chinese_language_and_literature \
--device cpu \
--batch_size 8 \
--output_path ./output \
--log_samples运行结果:
| Tasks |Version|Filter|n-shot| Metric | |Value | |Stderr|
|-------------------------------------------|------:|------|-----:|--------|---|-----:|---|-----:|
|ceval-valid_chinese_language_and_literature| 2|none | 0|acc |↑ |0.9565|± |0.0435|
| | |none | 0|acc_norm|↑ |0.9565|± |0.0435|
准确率有95.65%!成功了!我们是冠军!!!开个玩笑,这个模型不管从技术上还是商业上都没有任何价值,只是让我们走了遍模型训练的流程。
希望这篇文章能让你有所收获。